端到端(End-to-End):CPO 只是把交换侧的光学从面板移到 ASIC 边上,一条链路两端都必须有光学终端这件事从未改变;随着集群规模与端口速率上行,端到端光通道数持续增加。
机柜到机柜(Rack-to-Rack):AI集群的 Scale-Up(超大 Pod)+Scale-Out(更多机柜/机架) 同步推进;OCS/CPO 减少了电脊层,但增加了跨机柜的光电路,机柜到机柜的光口总量与纤路密度一起增长。
形态共赢:可插拔(含 LPO)在可维护/快速迭代场景继续放量;CPO/近封装在高密/高能效场景扩张。模块 → 光引擎/外置激光/高密线束只是形态迁移,总光学价值链更长、容量更大。
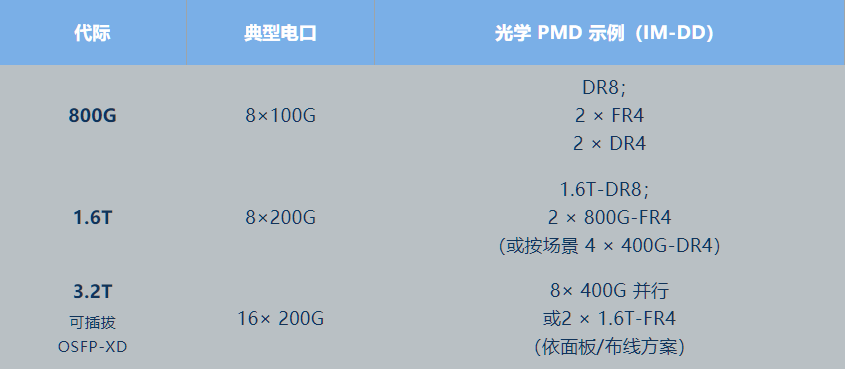
ATOP 路线:1.6T 可插拔批量+CPO 生态布局(光引擎、外置激光、扇出/高密互连)并行推进;同时验证 3.2T 可插拔(OSFP-XD+400G/lane,含 TFLN异质集成方案) 的可实现性,两条曲线共同抬升。